A continuación, se presenta una recopilación de los principales métodos de estimación para completar datos de precipitación:
1. Métodos de Series Anuales
1.1 Método de la Razón q
Se aplica a pares de estaciones, en donde A tiene los datos completos y B no.
La razón (q) entre los valores mensuales, anuales o medios, tiende a ser constante. Así, si se tienen dos estaciones (A y B), se determina “q” como:
q = Σ bi / Σ ai
Donde:
i: desde 1 hasta N
N: número total de datos de la serie
bi: dato i de la estación B
ai: dato i de la estación A
Por tanto, el valor bj faltante en la estación B, se obtiene como: bj = q * aj
Ventajas: permite rellenar medias de diferentes períodos y puede ser utilizado para valores mensuales y anuales.
1.2 Método de la Razón-Normal
Considera promedios de precipitación anuales en períodos iguales, no normales.
Se aplica a tres estaciones cercanas y uniformemente espaciadas con respecto a la estación en estudio.
Sea Px la precipitación anual de una estación X para un año determinado y utilizando los datos de dos estaciones A y B conocidas, se tiene que:
Px = 0.5 * ( Nx * PA / NA + Nx * PB / NB )
Donde:
Nx: precipitación promedio de la estación X, para el mismo período que se obtiene la lluvia promedio de la estación A (NA) y B (NB).
PA y PB: valores correspondientes a Px, de las estaciones A y B.
Ventajas: Este método se sugiere para cuando las diferencias en las precipitaciones anuales normales de las estaciones consideradas son mayores que un 10 %. Desventajas: la uniformidad de espaciamiento puede ser difícil de cumplir en algunas regiones. (1)
2. Completación por Regresiones Múltiples
Se recomienda para estimación de datos mensuales y anuales de la estación en estudio, en base a datos pluviométricos consistentes de una estación cercana.
Se establece una correlación como esta:
Y = a + b*X1 + c*X2 + … + n*Xi
Donde:
Y: valor de precipitación estimada
Xi: valor de precipitación en estaciones con información completa
a,b,c: constantes de regresión
Es más recomendable que el método de regresión Lineal, pero siempre que se cuente con estaciones cercanas y confiables. (2)
3. Métodos Multi Variantes
Todos los métodos se basan en el estudio de las correlaciones lineales individuales entre las series.
3.1 Razón Normal
Emplea tres estaciones.
Requiere realizar los cálculos con los valores de las series previamente normalizados mensualmente, en donde el coeficiente de correlación calculado es el de Pearson.
Calcula el dato incompleto, x(t) de una serie, a partir de los datos de las series de tres estaciones vecinas y contemporáneas que presenten un alto grado de correlación con la serie a completar, se estima a través de la expresión:

Donde:
x, x1 , 2 x y 3x: son las medias de las variables en cuestión de la serie incompleta y de las tres series vecinas respectivamente
x1(t) , x2(t) y x3(t): son los datos correspondientes a las series vecinas respectivamente.
- Ventajas: Este método juega con la variabilidad registrada en otras estaciones y con la razón proporcional entre ellas, y al tener tres estaciones se suaviza la influencia que podría tener un error en una de ellas.
3.2 Combinación Lineal Ponderada
La idea es sustituir la falta de datos a partir de los datos de series estadísticamente próximas, que son conocidas como vecinas.
Se tiene que para un mes t determinado, el dato incompleto x(t) se puede expresar como:

Donde:
ri: es el coeficiente de correlación de Pearson entre la serie i-ésima y la serie incompleta y xi(t) es el valor del instante t de la serie i-ésima.
Los coeficientes de correlación de Pearson deben calcularse con los valores de las series normalizados mensualmente.
Ventajas: El número de series que se utilizan para el completado es arbitrario en principio. (3)
4. Transformada Wavelet (TW)
Permite estudiar series de tiempo con una resolución baja para escalas grandes (Estructuras generales) y con resoluciones altas para escalas pequeñas (Estructuras finas). La construcción del algoritmo se puede dar de la siguiente manera:
Seleccionar dos estaciones vecinas, una vacía (f) y otra completa (g). Ambas deben pertenecer a la misma familia de distribución y con indicadores climáticos similares.
a) Estandarizar las señales de las estaciones siguiendo la metodología de Nakken.
b) Descomponer la señal con las siguientes ecuaciones, hasta un cierto grado N.

Donde:

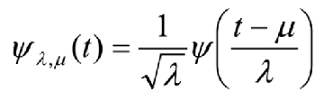
c) Promediar los valores de f en el nivel N.
d) Obtener la tendencia de f en el nivel N y los ruidos de g en todos los niveles.
e) Realizar el proceso inverso de la estandarización del paso b) para obtener la señal h.
f) Finalmente, los valores faltantes f son reemplazos los valores generados h.
A continuación, podemos apreciar un gráfico que muestra la reconstrucción de precipitaciones mediante el empleo del presente método.

Ventajas: Este método por su naturaleza, es independiente de la cantidad de información utilizada en el análisis. En consecuencia, es muy útil para emplearlo en situaciones dónde no se cuenta con suficiente información. (4)
5. Método de las Isoyetas

6. Neural Networks
Este modelo explora las variables de espacio y el tiempo para predecir patrones en los datos y estimar datos faltantes sobre precipitaciones. Esta capacidad ha sido confirmada mediante el uso de modelos matemáticos probados por Cybenko (1989) y Hornik (1989).
El proceso de estimación se realiza en dos fases. Primero, se modela la red y se pretende estimar los pesos o parámetros de la red. Luego, se procede a validar el modelo mediante la inserción de datos no empleados en la etapa de modelamiento.

T: Tiempo de retardo
T se elige de manera que Ϫ(τ) tienda a cero

m : Dimensión de inmersión
Se emplea esta ecuación para determinar la dimensión del “vecino falso” y estimar la dimensión de inmersión.

ω: Pesos de las conexiones
ω se elige de forma que minimice la siguiente expresión
Ecuación final:

El método básicamente se basa en corregir el error cuadrático con ayuda de los parámetros de ajuste usados. A continuación, se muestra un cuadro con el resultado del empleo del presente método.

7. Inverse-Distance-Weighted (IDW) Interpolation
El valor de la interpolación del campo pi dentro de (xi,yi) es el siguiente:

El valor de pn es conocido en el campo al medir n. Asimismo, los pesos ωi,n están dados por la siguiente expresión:

Donde Cx, Cy y Cz permite pesos anisotrópicos. Además, el factor de normalización Wi está dado por:
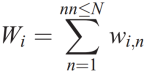
Ventajas: Este método tiene la capacidad de reproducir mediciones precisas y proveer información sin la interacción o interferencia del usuario. Además, este método ha demostrado eficiencia y credibilidad durante su uso en The National Wheater Service.
Desventajas: Se debe considerar las limitaciones del equipamiento y de su operación. Las mediciones individuales de precipitaciones están sujetas a error de operación mecánica y dependen de la calibración. (7)
Referencias
(1) http://www.imn.ac.cr/publicaciones/revista/2000/Julio/4-RAlfaro-Julio00.pdf
(2) http://eias.utalca.cl/Docs/pdf/Publicaciones/articulos_cientificos/pizarro_ausensi_aravena_sanguesa.pdf
(3) http://zucaina.net/Publicaciones/barrera-dea.pdf
(4) (http://www.senamhi.gob.pe/rpga/pdf/2010_vol02/art7.pdf
(5) http://www.srh.noaa.gov/abrfc/?n=map#techniques
(6) http://water.usgs.gov/wrri/07grants/progress/2007FL202B.pdf
(7) http://www.tucson.ars.ag.gov/unit/publications/PDFfiles/1872.pdf