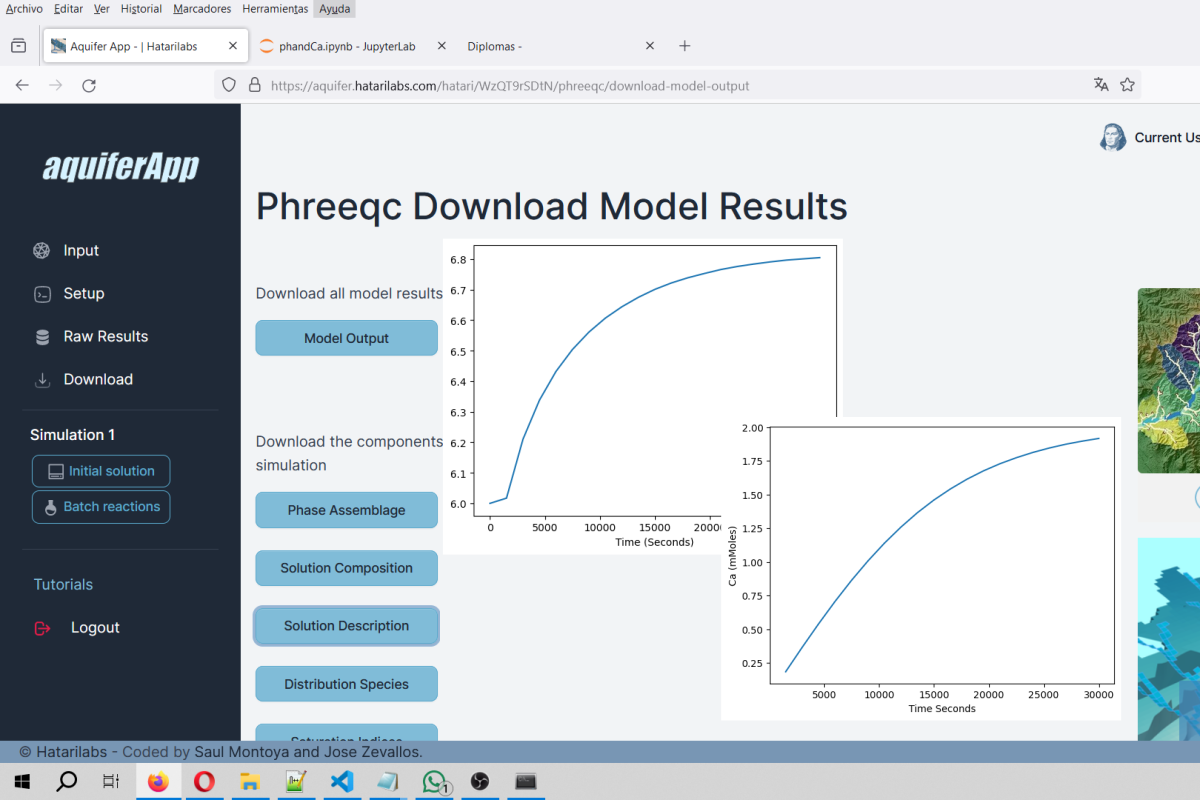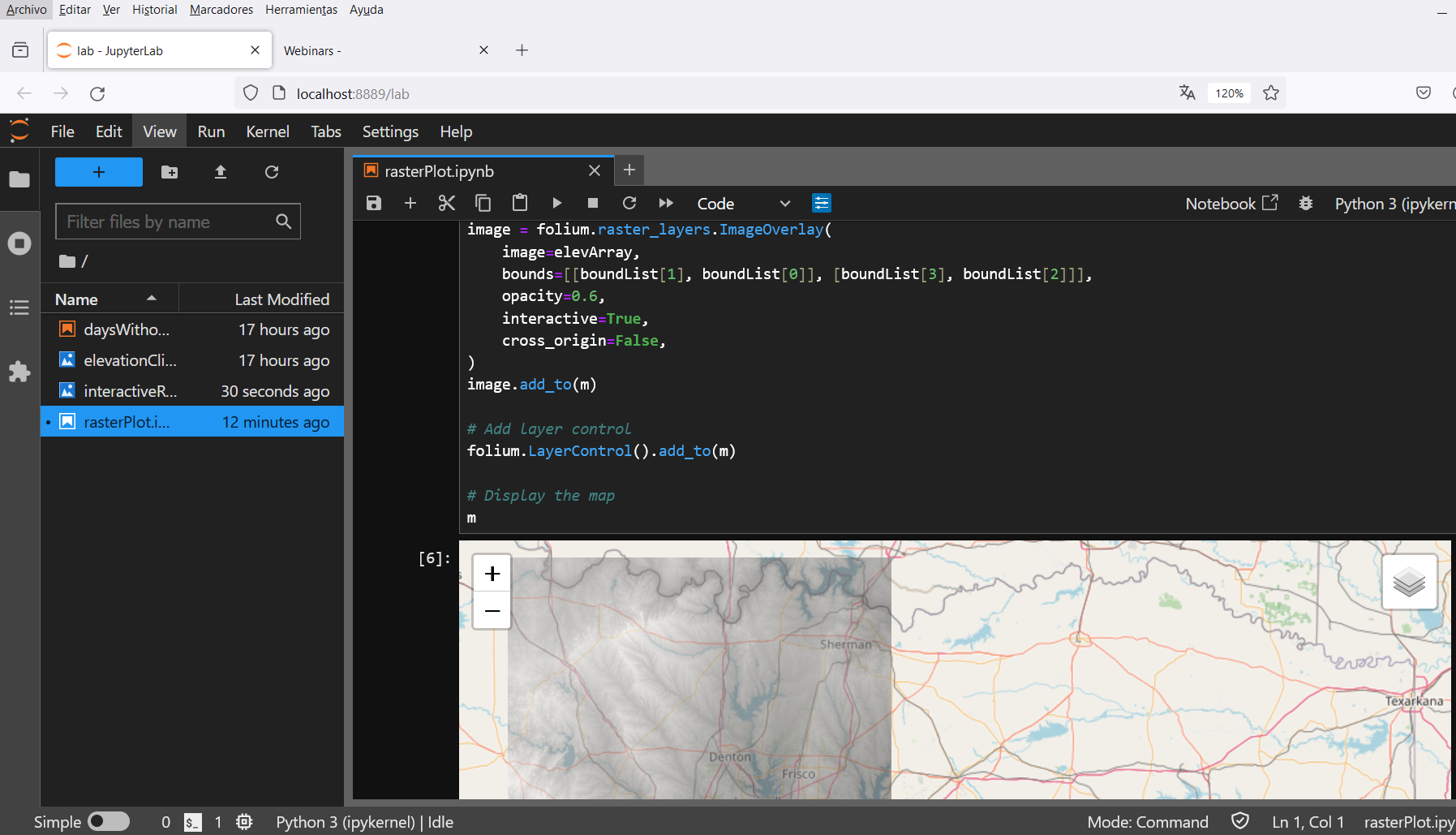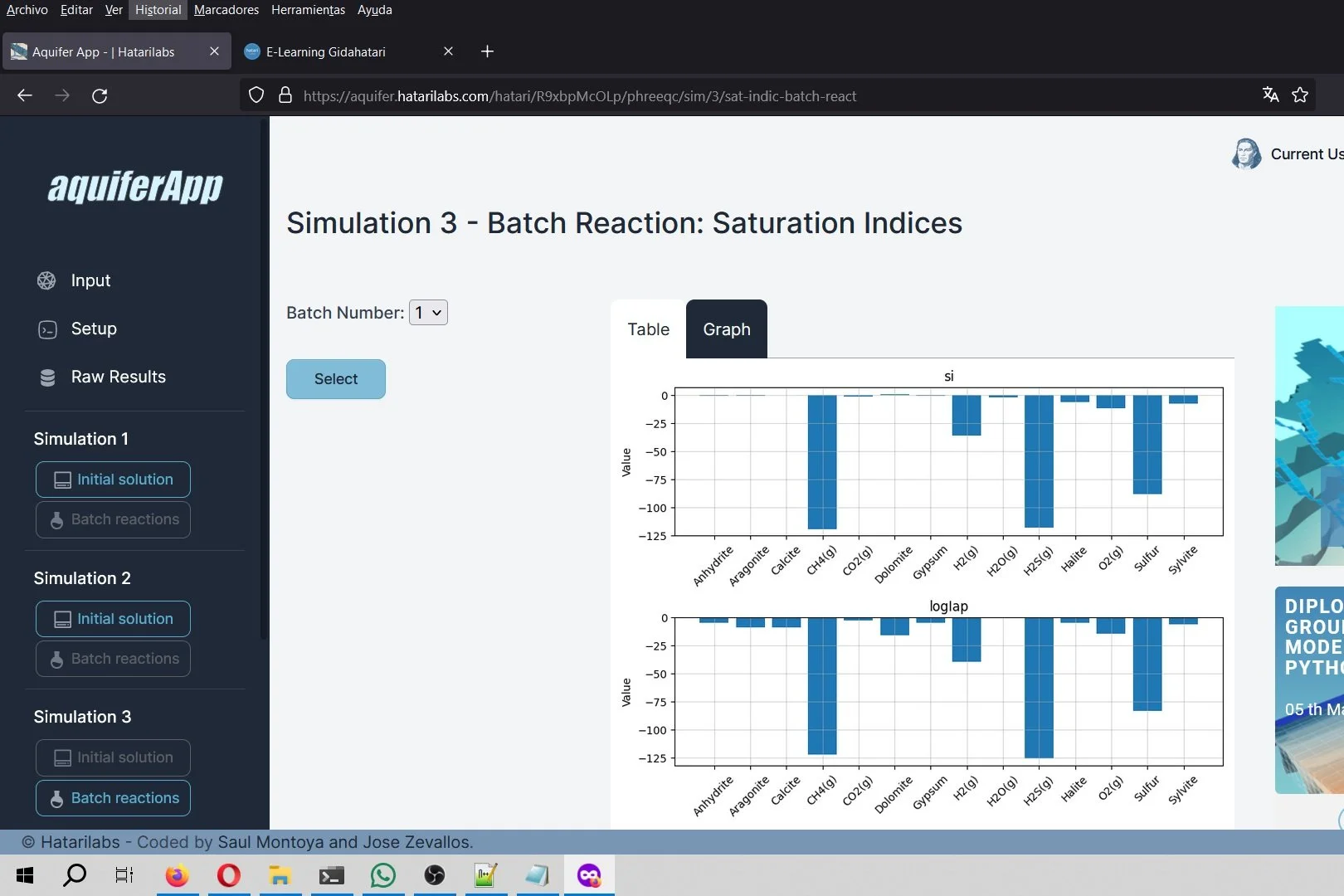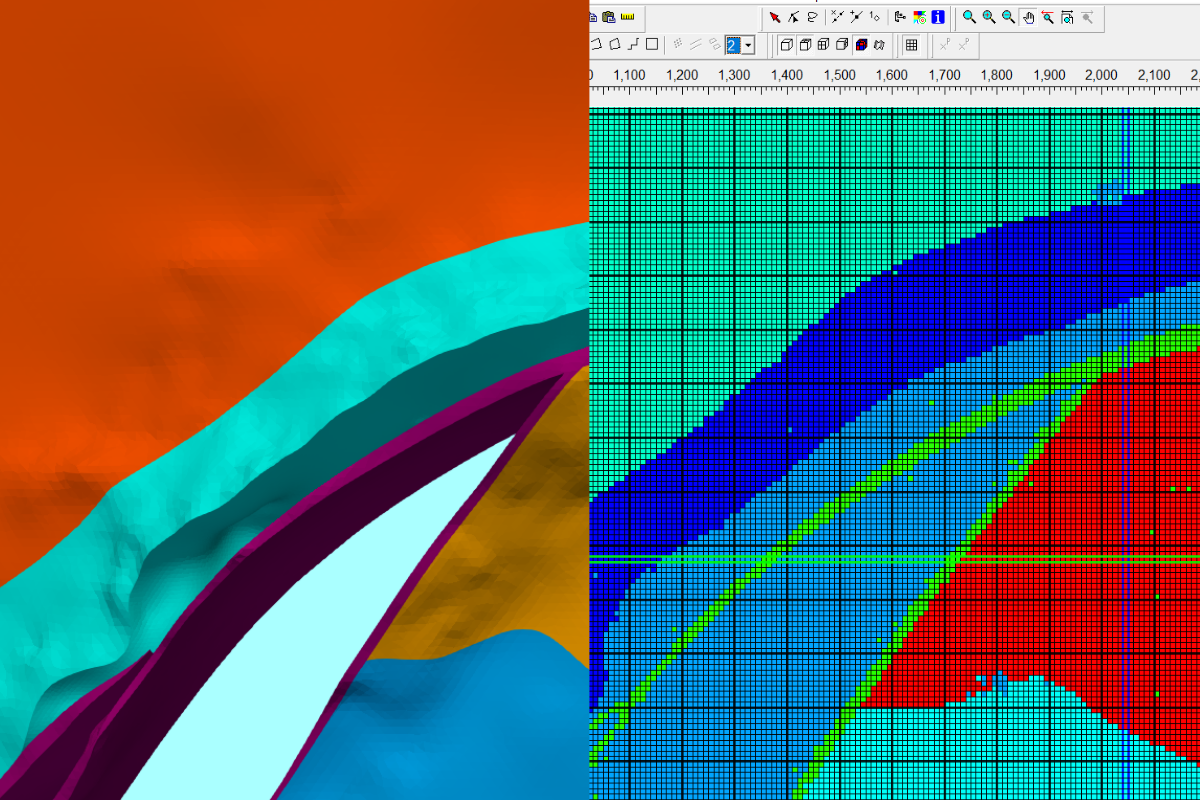
Los datos reportados en informes muchas veces estan en formato digital como PDF, o peor aun como una imagen. El proceso de recuperación de datos es manual y puede ser muy lento dependiendo de la cantidad de datos que se quieran procesar. Una manera inteligente de acceder a estos datos es mediante un lenguaje de programación como Python, y paquetes especialidos de manejo de datos como Tabula-py y Pandas.
Este tutorial muestra el procedimiento completo de importación de un pdf en Python3 y la configuracion de un Dataframe de Pandas específico para luego exportarlo como archivo de MSExcel.
Este tutorial se realizó utilizando Anaconda que pueden descargar de:
https://www.anaconda.com/download/
Se requiere tener Java instalado:
https://www.java.com/es/download/
Tutorial
Código en Python
Este es el código completo en Python 3 para este tutorial:
from tabula import read_pdfdf = read_pdf('../Pdfs/Libro1.pdf',
guess=False,
pandas_options={'skiprows':[0,1],'header':None}
)
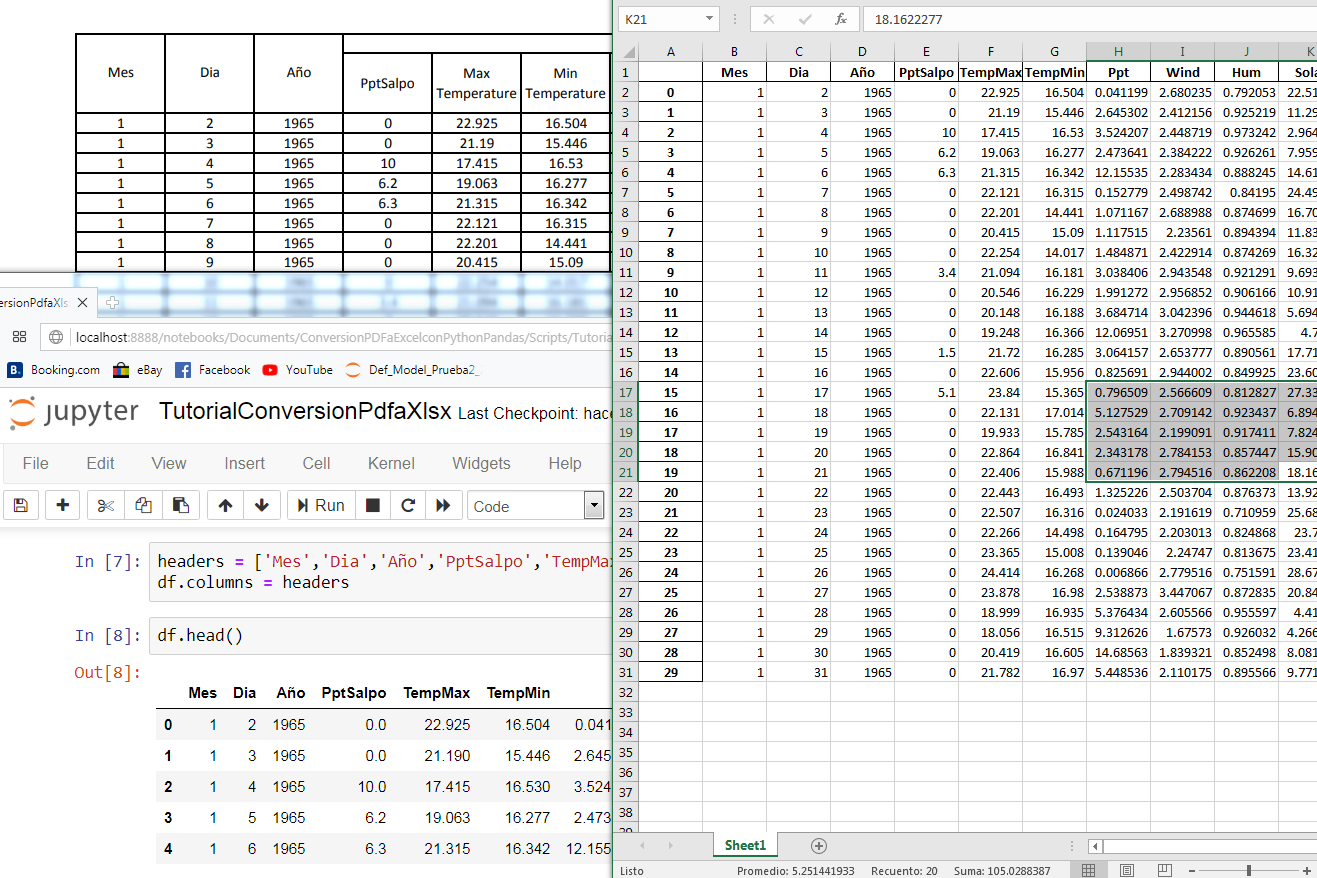
df.head()headers = ['Mes','Dia','Año','PptSalpo','TempMax','TempMin','Ppt','Wind','Hum','Solar']
df.columns = headersdf.head()df.to_excel('../Xls/Libro1.xlsx')Datos de ingreso
Usted puede acceder a los datos y codigos utilizados en este tutorial de este enlace.