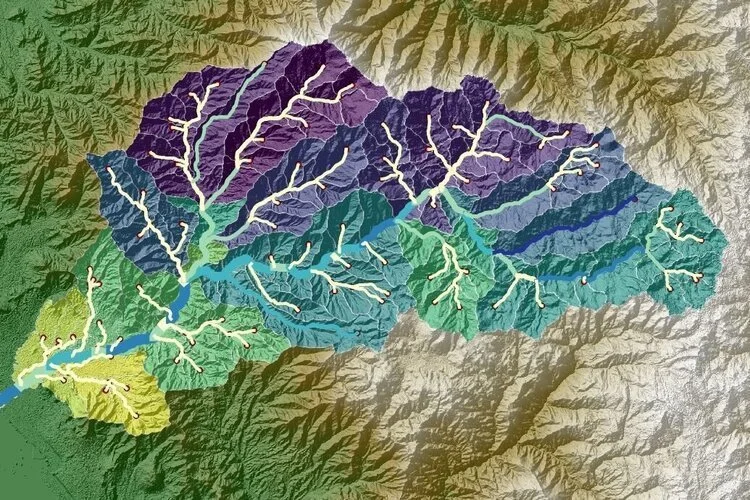
Por lo general, utilizamos enfoques probabilísticos cuando se trata de eventos extremos ya que el tamaño de los datos disponibles son escasos para hacer frente a la máxima para un periodo de retorno determinado.
Datos de precipitación presentan desafíos cuando tratamos de ajustar a una distribución estadística. Este es un ejercicio hecho con 10 años los registros de precipitación para la estación de Morropón (Piura-Perú) afectadas por los fenómenos de El Niño y La Niña en los años 98 y 99, respectivamente (descargue los datos aquí).
El procesamiento de los datos se realizó con Python en la interfaz Notebook IPython. Puedes utilizar la versión IPython cloud en wakari.io para realizar este ejercicio.
1. Importar datos
Primero importamos los datos y la trama usando la biblioteca panda.
In[]:%pylab inline
%cd C:\WRDAPP\Curso_PyH\AuxData
import pandas as pd
import numpy as np
datos = pd.read_csv('PptMorropon.csv',
index_col=0, na_values=[-9999], parse_dates=True)
datos.plot()
Out[]:

2. Crear un histograma de la precipitación
Creamos un histograma de los valores de la precipitación, lo que significa valores superiores a 0.
In[]:datos[datos>0].hist() Out[]:

Como podemos ver, el conjunto de datos de la precipitación es bastante sesgada. Vamos a trabajar en la distribución para llegar a obtener una "incertidumbre aceptable" en la distribución estadística.
3. Gráfico de la distribución normal y lognormal
Calculamos el promedio y la desviación estándar
In[]:promedio = datos[datos>0].mean() desviacion = datos[datos>0].std()
Entonces calculamos la distribución estadística correspondiente
In[]:tabulaciones=np.arange(-40,51,0.1) distnormal = stats.norm.pdf(tabulaciones, loc=promedio, scale=desviacion) distlognormal = stats.pearson3.pdf(tabulaciones,skew=1,loc=promedio, scale=desviacion)
Y graficamos los datos
In[]:datos[datos>0].hist(bins=100,normed=True) plot(tabulaciones,distnormal, color='red', label='distnormal') plot(tabulaciones,distlognormal, color='grey', label='distlognormal') xlim(0,30) legend(loc='upper right')

Dado que el ajuste de la distribución normal y lognormal dependen de la media aritmética y la desviación estándar (medidas de ubicación), son afectados por eventos extremos. Es por ello que tenemos que "dar forma" a los datos para tener una precipitación que se ajusta razonablemente a una distribución estadística.
4. Recorte de los datos
Decidimos cortar el 10% de los datos inferiores y 20% de los superiores.
In[]:print datos_ppt.quantile(0.10),datos_ppt.quantile(0.80) Out[]: Ppt_mm 0.4 dtype: float64 Ppt_mm 8.44 dtype: float64
Cortamos los datos utilizando los cuartiles obtenidos
In[]:datos_ppt_min=datos_ppt[datos_ppt>0.4] datos_cut=datos_ppt_min[datos_ppt_min<8.44] datos_cut.describe() Out[]: Ppt_mm count 295.000000 mean 2.383729 std 2.029009 min 0.400000 25% 0.800000 50% 1.600000 75% 3.500000 max 8.400000
5. Para representar datos recortados
Definimos las nuevas estadísticas a partir de los datos recortados y graficamos las distribuciones estadísticas.
In[]: promedio_cut=datos_cut.mean() desviacion_cut=datos_cut.std() tabulaciones_cut=np.arange(-10,20,0.1) distnormal_cut = stats.norm.pdf(tabulaciones_cut, loc=promedio_cut, scale=desviacion_cut) distlognormal_cut = stats.pearson3.pdf(tabulaciones_cut,skew=1,loc=promedio_cut, scale=desviacion_cut) datos_cut.hist(normed=True,bins=15) plot(tabulaciones_cut,distnormal_cut, color='red', label='distnormal') plot(tabulaciones_cut,distlognormal_cut, color='grey', label='distlognormal') xlim(0,15) legend(loc='upper right')
Out[]:

Ahora tenemos dos distribuciones estadísticas que se ajustan mejor a la precipitación (logarítmica y lognormal). Podemos decir que la distribución lognormal se ajusta mejor a los datos registrados.