La evaluación de procesos de precipitación, escorrentía, enrutamiento, así como la infiltración requieren de datos de precipitación, caudal, temperatura y radiación a escala diaria. Los datos requeridos por los modelos hidrológicos deben ser confiables y estar completos en el periodo de estudio. Muchas veces los datos de estaciones de precipitación, aforo, entre otros se presentan incompletos en varias partes siendo posible su completación mediante métodos numéricos, regresiones o algoritmos de inteligencia artificial.
Keras es una plataforma de alto nivel para redes neurales escrita en Python. Esta plataforma esta enfocada en permitir una experimientación rápida de los datos de entrada. Keras soporta redes convulsionales y recurrentes y combinaciones de ellas, además está diseñada para correr tanto en PCs como en computadoras avanzadas de multiprocesadores.
La ventaja de utilizar inteligencia artificial en scripts y librerías como Python - Keras es la practicidad en el manejo de los datos, las opciones de configuración de las redes neurales dependiendo de los datos de entrada y la capacidad de procesamiento y representación de grandes series de datos.
Para instalar Keras dentro de Anaconda 3 le recomendamos seguir este tutorial.
Tutorial
Parte 1
Parte 2
Código
Este es el código completo en Python para correr la red neural:
get_ipython().magic('pylab inline')
import pandas as pd
import numpy as np
TodasEstaciones = pd.read_csv('Est1_Est2_Est3.csv',index_col=0,parse_dates=True)
TodasEstaciones.head()
TodasEstaciones.loc['2014-11-01':'2015-03-31'].plot(subplots=True, figsize=(12, 8)); plt.legend(loc='best')
xticks(rotation='vertical')
import datetime
#we create a date column to extract the week number
TodasEstaciones['date']=TodasEstaciones.index
#apply a lambda function to the whole panda dataframe column
TodasEstaciones['week'] = TodasEstaciones['date'].apply(lambda x: x.isocalendar()[1])
#drop the date column because we dont need it
del TodasEstaciones['date']
#let see our dataframe
TodasEstaciones.head()
#creation of a correlation plot with seaborn
import seaborn as sns
corr = TodasEstaciones.corr()
sns.heatmap(corr,
xticklabels=corr.columns.values,
yticklabels=corr.columns.values)
#Definition of training sets
X_train = TodasEstaciones.loc['2015-01-20':'2015-03-27',['Est1','Est3','week']].astype(float32).values#,'week']] # Est 1, 3 and #week
y_train = TodasEstaciones.loc['2015-01-20':'2015-03-27','Est2'].astype(float32).values # Est 2
# Import `StandardScaler` from `sklearn.preprocessing`
from sklearn.preprocessing import StandardScaler
# Define the scaler
scaler = StandardScaler().fit(X_train)
# Scale the train set
X_train = scaler.transform(X_train)
X_train[:20]
from keras.models import Sequential
from keras.layers import Dense
model = Sequential()
model.add(Dense(12, activation='linear', input_shape=(3,)))
model.add(Dense(8, activation='linear'))
model.add(Dense(1, activation='linear'))
model.summary()
model.compile(loss='mean_squared_error',
optimizer='adam',
metrics=['accuracy'])
model.fit(X_train, y_train,epochs=200,verbose=0)
y_pred = model.predict(X_train)
y_pred[:10]
plot(TodasEstaciones.loc['2015-01-20':'2015-03-27'].index,y_pred,label='Predicted')
TodasEstaciones['Est2'].loc['2015-01-20':'2015-03-27'].plot()
figsize(12,8)
ylim(0,40)
legend(loc='best')
#Get the prediction for the train set
X_missing = TodasEstaciones.loc['2014-11-23':'2015-01-11',['Est1','Est3','week']].astype(float32).values
# Import `StandardScaler` from `sklearn.preprocessing`
from sklearn.preprocessing import StandardScaler
# Define the scaler
scaler = StandardScaler().fit(X_missing)
# Scale the train set
X_missing = scaler.transform(X_missing)
y_missing = model.predict(X_missing)
y_missing = y_missing.reshape([50]).tolist()
TodasEstaciones['Est2_Completed']=TodasEstaciones['Est2']
TodasEstaciones['Est2_Completed'].loc['2014-11-23':'2015-01-11']=y_missing
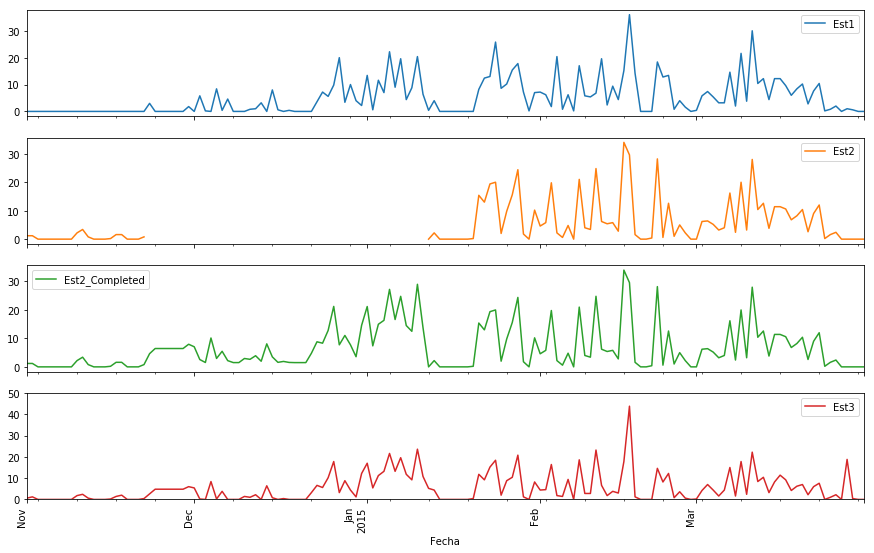
TodasEstaciones.loc['2014-11-01':'2015-03-31',['Est1','Est2','Est2_Completed','Est3']].plot(subplots=True,
figsize=(15, 10)); plt.legend(loc='best')
xticks(rotation='vertical')
ylim(0,50)
Datos de Entrada
Descargue los datos de entrada de este enlace.